
Oct 09, 2025
Supply chains used to be “backstage.” Today, they are center-stage and under strain.
Geopolitical shocks, vendor concentration, cyber exposure, labor volatility, and weather all conspire to turn small hiccups into expensive disruptions.
Recent research shows companies slipping back into ad-hoc risk reporting after a brief surge of discipline, meaning many teams discover issues only when customers already feel the pain.
That’s why supply chain incident management matters.

When detection, communication, triage, and recovery run as a routine, not a scramble, you cut loss, protect customers, and keep audits sane.
This guide gets practical: the building blocks (forms, bridge calls, RCA), a clear end-to-end process, what to look for in an incident management application, and a simple way to decide.
Core elements of supply chain incident management (and how they work together)
Great programs have the same three building blocks. Use them well, and everything else gets easier; skip them, and you’ll keep fighting the same fires.
The incident management form: capture once, reuse everywhere
An incident management form is the system’s first truth.
It standardizes what “good” reporting looks like: who, what, when, where, impact so far, suspected cause, immediate actions taken, attachments (photos, bills of lading, sensor logs), and who’s on point next.
Think of it like ICS-style discipline adapted to operations: concise, complete, and usable by anyone stepping in mid-stream. (Emergency management uses ICS forms for this reason: structured, repeatable reporting for significant events.)
Why it matters: Clear intake reduces back-and-forth, shortens time to triage, and creates the evidence trail you’ll need for insurance, compliance, and root-cause analysis later.
The bridge call: align people fast when the stakes are high
A bridge call (sometimes called a major-incident bridge or war-room) is a time-boxed, facilitator-led call where operations, suppliers, logistics, IT, safety, and customer teams converge.
The purpose is not endless diagnosis; it’s to align on impact, roles, priorities, and next actions while maintaining a single comms channel.
Mature incident playbooks define who speaks, how to keep the call focused, and when to spin up a separate technical huddle so the bridge stays clear. (Best-practice guides in incident management emphasize role clarity, severity models, and a documented lifecycle before the big one hits.)
Why it matters: Done well, a bridge prevents chaos: one channel, one set of owners, one current truth.
RCA in incident management: fix what actually failed
What is RCA in incident management? Root cause analysis is a structured method to understand why the incident occurred, so you can prevent recurrence.
It goes beyond symptoms to underlying causes and contributing factors, using tools like 5 Whys, fishbone diagrams, Pareto, fault tree, and A3.
The goal is corrective actions that address the cause, not just clean up the mess. (Quality bodies define RCA as a family of techniques aimed at uncovering true causes and guiding effective, lasting fixes.)
Why it matters: Without RCA, you’ll rack up the same losses with new ticket numbers.
The supply chain incident management process (step by step)
Use this once per quarter on a real flow, then refine. Simple beats elaborate, especially when third parties are involved.
Detect and signal
Use upstream triggers: EDI exceptions, ASN mismatches, telematics, temperature/pressure alerts, quality holds, cyber vendor alerts, or supplier notice. The goal is to spot anomalies before the customer does. (Digitized supply chains outperform here; firms that sustain investment in monitoring and resilience weather shocks better.)
Report via the incident management form
Capture essentials in minutes, not hours. Require fields for impact (orders, shipments, SKUs, plants affected), time started, likely scope, and immediate containment. Attach evidence. Auto-assign a case number and owner. (ICS-style standardization improves clarity under pressure.)
Stand up the bridge call (if severity warrants it)
Set severity from a simple matrix (volume/customer/regulatory harm). Invite only necessary roles. The facilitator keeps a live log: impact, actions, owners, and ETAs. If technical deep-dives begin, spin them to a separate thread and keep the bridge on impact and decisions. (Major-incident playbooks stress role clarity and lifecycle discipline.)
Triage and containment
Stabilize the system: reroute shipments, switch carriers, move to safety stock, disable a supplier endpoint, issue a quality hold, notify customers proactively if SLAs will slip. Track containment actions as discrete tasks with owners and deadlines.
Communicate and coordinate
Establish a single, repeating cadence (e.g., 30-minute updates). Keep notes, decisions, and customer-facing language synchronized. For multi-vendor incidents, share only the necessary facts, but do it consistently.
RCA and corrective actions
Within 24–72 hours (depending on severity), run a facilitated RCA. Identify the root cause and contributing causes (process, training, vendor controls, system defects). Log corrective actions with required evidence for closure. Track a verification step two weeks later to ensure the fix held. (This is the heart of “don’t repeat the incident.”)
Recovery and post-incident review
Confirm orders recovered, suppliers stabilized, controls updated, and customer comms closed. Then run a blameless post-incident review: what went well, what failed, what to change in the playbook, how to refine indicators and thresholds. Tie follow-ups to owners with dates.
Test and improve
Schedule tabletop exercises, including suppliers, and rotate scenarios (quality, logistics, cyber, EHS). ISO 22301/continuity guidance and industry advisories repeatedly emphasize practicing the plan and updating based on lessons learned.
How to choose a supply chain incident management application (so it actually gets used)
Selecting software is less about feature bingo and more about execution fit.
Use the criteria below to separate resilient programs from “best-effort” ones, they align naturally with application incident management needs.
Ease of reporting (intake speed and quality)
If reporting is slow, signals arrive late. Look for structured web/mobile forms with conditional logic, photo/file capture, barcode or PO fields, and auto-routing by site, product, or supplier. The best tools make the incident management form fast to complete and impossible to skip.
Collaboration that shortens bridge calls
Your application should support severity tagging, templated comms, assignment, and a shareable activity log. You don’t need built-in voice; you need clarity, a single place where impact, actions, and owners stay in sync during a bridge call. (This mirrors major-incident guidance: one current truth.)
RCA and corrective actions that require evidence
Insist on workflows that enforce evidence-backed closure: photos, documents, checklists, and supplier attestations. Bonus points for built-in RCA templates (5 Whys, fishbone) and an easy way to verify the fix after two weeks.
Dashboards and indicators that predict trouble
You need more than lagging counts. Track leading indicators like late reports, overdue actions, repeat incidents by supplier or site, skipped checks, and cycle-time creep. Executives should see posture; owners should see what to do next.
Audit and compliance readiness
Your tool should produce audit-ready trails: who reported what and when, who approved, what evidence closed the action, and how risk was mitigated. If you operate under ISO, FDA, OSHA, or customer audits, this saves weeks each year. (Standardized forms and continuity practices exist for a reason.)
Integration and data model (avoid a new silo)
APIs and connectors to TMS/WMS/ERP, QMS, EDI, HRIS, and identity (SSO) reduce swivel-chair work and let you reuse operational data (orders, SKUs, suppliers, routes) inside incidents. The right incident management application ensures evidence and ownership live with the work, not scattered across inboxes.
Why Aclaimant is a strong choice for supply chain incident management
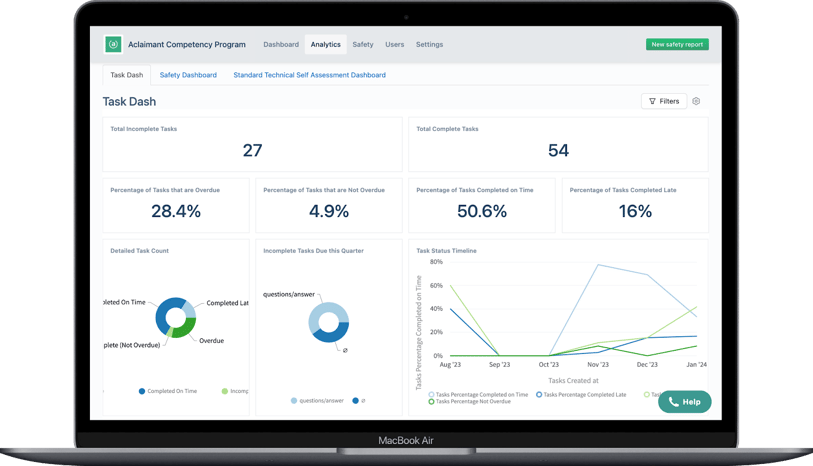
When supply chain incidents hit, the difference between a quick recovery and a drawn-out scramble is simple: how fast you capture the facts, how clearly you assign owners, and how reliably you close actions with proof.
That’s execution, not theory. Aclaimant is built for exactly that rhythm.
Instead of living as a policy library, Aclaimant sits where supply chain incident management actually happens: intake, triage, corrective actions, inspections, and claims.
It turns scattered emails and spreadsheets into one connected record of work, so the people fixing the problem see the same truth as the people reporting it.
If your teams are battling application incident management chaos, late incident reports, unclear responsibility, and “done” without evidence, Aclaimant gives you a steady backbone: structured reporting, owner-driven follow-through, and dashboards that surface issues before customers feel the pain.
Key features that matter in supply chain incident management:
Structured incident intake and routing (your incident management form done right)
Aclaimant standardizes the incident management form so every report captures the essentials the first time: what happened, where, impact, attachments (photos, bills of lading, sensor logs), and severity.
Routing rules send each case to the right owner by site, product, lane, or supplier. That cuts back-and-forth and starts triage in minutes, not hours.
Owner-driven corrective actions with evidence (so RCA actually sticks)
Aclaimant turns RCA in incident management from a slide into standard work. Every corrective action has a single owner, a due date, and required proof of completion: photos, checklists, inspection results, and supplier attestations. Add a verification step to confirm the fix held. No evidence, no closure. That’s how repeat incidents finally stop repeating.
Dashboards and leading indicators (see problems before they escalate)
Leaders and frontline owners get live views of what matters: late incident reports, overdue tasks, repeat incidents by supplier/site, skipped checks, and cycle-time creep.
Exception queues and KRIs make priorities obvious, while summaries keep executives focused on posture and trend, not just last month’s totals.
Safety, compliance, and inspections in the same flow (audit-ready by default)
Permits, safety walkdowns, inspections, and training records can live alongside incidents and actions. Evidence isn’t scattered across inboxes; it’s attached to the work itself. When audits or customer reviews hit, you produce a complete, chronological trail in clicks.
Connected claims management (from FNOL to resolution)
If an incident becomes a claim, you don’t start from scratch. First notice of loss ties back to the originating record, so facts, attachments, and actions carry forward. That continuity reduces rework and keeps adjusters and operations aligned.
Integrations that avoid a new silo (work with the systems you already run)
Aclaimant can slot into your environment, pulling and pushing data to the systems you rely on (think TMS/WMS/ERP, QMS, HR/identity). That means you reuse order, SKU, and supplier context inside incidents and export clean evidence and reports out, without swivel-chairing between tools.
The bottom line? If your program goal is simple: work that’s visible, owners who are accountable, and evidence captured as the work happens, Aclaimant fits. It’s purpose-built for documenting incidents, standardizing workflows, and turning corrective actions into results across your supply chain.
Ready to see it in action? Schedule a demo of Aclaimant to see how one connected platform can make supply chain incident management faster to run and far easier to prove.
Common pitfalls that quietly break supply chain incident management

Even the best supply chain incident management programs can unravel if certain traps go unchecked.
These pitfalls don’t always show up in dashboards, but they quietly slow response, create confusion, and let the same failures repeat. Recognizing them early is the first step to keeping your program resilient.
Vague intake creates a fog of war
When the incident management form is mostly free-text or missing required fields like impacted orders/SKUs, site, supplier, and immediate actions, teams spend the first hours chasing basics.
Incomplete intake slows triage, makes severity calls guesswork, and destroys your audit trail. Attachments (photos, BOLs, sensor logs) go missing, and every update spawns a new version of “the truth” in email or chat.
Tell-tale signals
- Lots of follow-up pings (“who’s affected?”, “do we have photos?”).
- Duplicate tickets or conflicting incident summaries.
- Post-incident gaps: claims/audits asking for evidence you can’t find.
Bridge chaos turns a crisis call into a distraction
A bridge call without a severity model, a facilitator, or a time box quickly devolves into status theater. Too many voices jump in, deep technical debates hijack the room, and actions aren’t captured.
The result is slower containment, contradictory customer updates, and a team that exits the call no clearer than when it joined.
Tell-tale signals
- Calls run long with no decisions or owners assigned.
- Side huddles inside the main call; people ask for a “recap” afterward.
- Customer-facing updates conflict with what ops believes is true.
Symptom fixes masquerade as progress
Closing tickets without RCA in incident management just resets the clock. Workarounds (reroute shipments, toggle a control, swap carriers) may restore flow, but don’t address the cause: process gaps, training, supplier controls, or a system defect.
The same incident returns under a new number, and executives wonder why nothing changes.
Tell-tale signals
- Repeat incidents by the same supplier/site or SKU.
- Corrective actions marked “done” without proof attached.
- Teams debate causes in retros, then nothing changes upstream.
Tool sprawl recreates the problem you’re trying to solve
Email, spreadsheets, shared drives, and chat threads are not application incident management. When reporting is in one place, actions in another, and evidence in a third, you’ve created a control gap you can’t see.
Without a central system, or at least tight integration, rekeying errors creep in, handoffs fail, and audits become archaeology.
Tell-tale signals
- Multiple trackers for the same incident; weekly reconciliations to “match” data.
- Owners change mid-stream because responsibilities live in people’s heads.
- Auditors ask, “Where is the official record?” and no one agrees.
No cadence means improvements never stick
Incident management isn’t “set and forget.” Without a monthly/quarterly rhythm to review indicators, overdue actions, and lessons learned, drift wins.
Teams stop watching leading signals (late reports, skipped checks), actions age out, and the next event plays out just like the last one, only costlier.
Tell-tale signals
- Aging corrective actions; verification steps never scheduled.
- Dashboards show stale data or only lagging counts.
- Tabletop exercises get postponed until “after peak season,” then never happen.
How do these pitfalls compound? Each on its own slows you down; together they multiply: vague intake feeds bridge chaos, symptom fixes thrive without RCA, tool sprawl hides the truth, and lack of cadence guarantees déjà vu.
Naming these failure modes and watching for the signals keeps your supply chain incident management program honest, measurable, and resilient.
Conclusion: A simple rhythm beats big promises
Supply chains stay resilient when incident management is routine, not an improvisation.
Standardize your incident management form, run focused bridge calls, and treat RCA as non-negotiable.
Then pick an incident management application that makes this rhythm easy: fast intake, clear ownership, evidence-backed closure, leading indicators, and integrations that keep data in one flow.
If your biggest gaps are scattered reports, slow follow-through, and audits that steal weeks, Aclaimant stands out.
It connects incident intake, routing, corrective actions, and dashboards in a single record of work, so you see risk sooner and close the loop faster.
Schedule a demo to see how one connected platform turns supply chain incident management into a repeatable advantage.
FAQs

Comments